







Building mission-critical blockchain indexing for AI & Crypto
Modern AI agents and crypto trading systems rely on real-time blockchain indexing. This article explains why most blockchain indexers fail under sustained load and how production-grade indexing infrastructure prevents stale data, lag, and execution failures.


Early blockchain indexing systems were primarily designed to support analytics use cases, such as dashboards, historical queries, and batch-oriented data access. In these contexts, moderate latency, partial lag, and occasional downtime were generally acceptable.
Those days are over. Today, real-time indexed data sits directly in the execution path. Trading engines, liquidation bots, and AI agents now rely on a live view of the chain to function. When an indexer lags, these applications fail to execute — leading to unprocessed trades, missed liquidations, and inaccurate position data.
Modern blockchain indexers must now operate as real-time production infrastructure rather than analytics tools.
Why blockchain indexers crash under sustained load
Most teams evaluate performance based on peak throughput. They want to know how many thousands of events a system can process in a vacuum. In production, that number is irrelevant.
The true challenge is sustained load. Blockchain indexing rarely fails because of a single large block. They fail because of sustained pressure.
Three patterns appear repeatedly:
- Ingestion lag during high volatility bursts
- Query slowdowns caused by concurrent read and write traffic
- Retry storms are triggered when an RPC source begins to degrade
These failures are often invisible. A system may report perfect uptime while falling behind in the chain.
The key metric is block distance, the gap between the chain head and the indexed database. Systems designed for sustained throughput focus on consistency rather than peak benchmarks.
Why cloud-only blockchain indexers fail
While cloud infrastructure offers flexibility, the high-intensity nature of blockchain ingestion requires high-performance hardware.
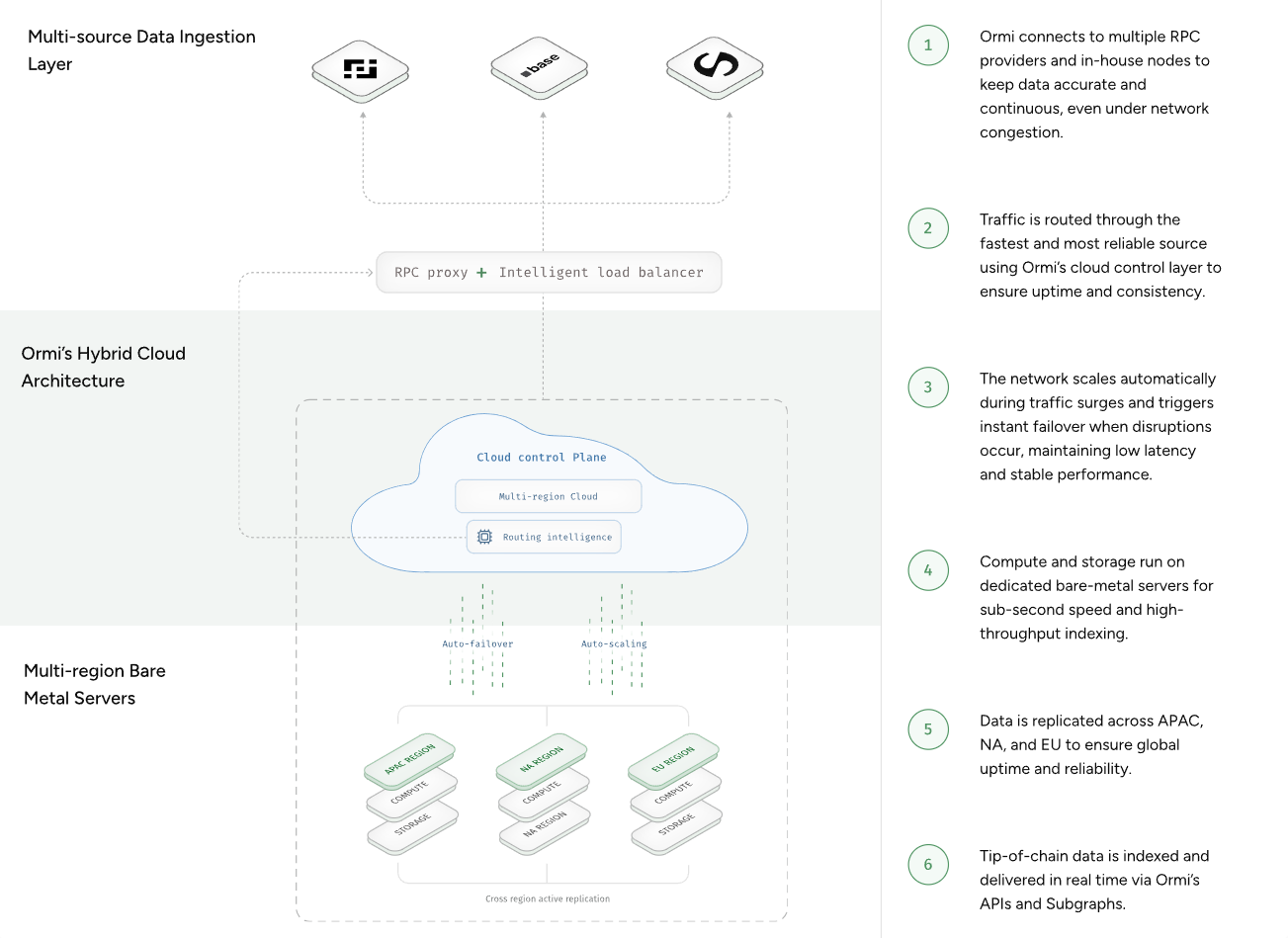
Some teams address this by separating ingestion workloads from shared cloud environments. One approach is a hybrid architecture that combines bare-metal ingestion with cloud orchestration.
Ormi follows this model.
Running ingestion workloads on bare-metal eliminates the noisy-neighbor effects that often appear in shared cloud environments. We maintain orchestration and control-plane services in the cloud for speed. This architecture is a deliberate trade-off. It is more costly, but it guarantees data availability. Separating the data plane from the control plane prevents network surges from affecting indexing freshness.
Learn more about how to choose a blockchain indexer.
RPC routing vs retry failures
Indexing systems today handle a slow RPC endpoint by retrying the request. Under heavy load, this becomes a systemic failure mode. Constant retries add to the congested load, which can further choke the struggling node. This is one reason many blockchain indexers struggle to maintain real-time synchronization across chains.
Some indexing systems address this with dynamic RPC routing.
Ormi implements this through an RPC proxy layer. Instead of retrying a failing path, our RPC Proxy monitors real-time performance and shifts traffic to healthy sources or different regions automatically.
This creates a bounded failure environment. If one source goes down, the system moves on rather than attempting to revive an unhealthy node.
Reliability is structural
Reliability cannot be a configuration toggle. It must be a structural property. High-availability indexing requires structural redundancy.
We isolate the query layer from the ingestion layer. This prevents a surge in user queries from slowing down the ability of the system to keep up with the blockchain. We also prioritize incremental recovery over full re-indexing. In large-scale systems, reindexing from genesis is a catastrophic recovery plan. Ormi preserves partial progress, allowing the system to pick up exactly where it left off after a crash.
Learn more about Ormi’s technology.
Beyond the uptime myth
Uptime is a deceptive metric. An indexer can be online while being a hundred blocks behind the tip of the chain. A blockchain indexer is only useful if it remains within a few blocks of the chain head under sustained load.
Read more: How Ormi keeps Ostium, a RWA protocol with $150M in daily volume, within 10 blocks of the chain tip.
Ormi prioritizes observability into synchronization status and workload isolation. We treat indexing as mission-critical production infrastructure. Our design philosophy is simple: assume failures will happen.
The goal is to constrain the impact of those failures so they do not cascade into a total system blackout. We have intentionally traded lower costs for higher stability. Data freshness and accuracy become the metrics that matter most.
About Ormi
Ormi is the next-generation data layer for Web3, purpose-built for real-time, high-throughput applications like DeFi, gaming, wallets, and on-chain infrastructure. Its hybrid architecture ensures sub-30ms latency and up to 4,000 RPS for live subgraph indexing, sub-10ms responses across 100+ API schemas, and a powerful SQL engine for historical and AI-ready data.
With 99.9% uptime and deployments across ecosystems representing $50B+ in TVL and $100B+ in annual transaction volume, Ormi is trusted to power the most demanding production environments without throttling or delay.