







Why AI Agents Need Composable Data Systems
AI agents will not scale on rigid schemas and pre-built dashboards. They need composable data systems that expose small, well-scoped datasets, rich metadata, and interfaces agents can assemble on demand.


The inventors of Unix were humble enough to recognize that they couldn’t predict everything that people would want to do. They were also smart enough to recognize that some patterns were common to multiple workflows. These insights led them to design a minimalist operating system with the primitives necessary to allow small, sharp programs to work together. Programmers could then solve the most complex problems by stitching these tools together in any number of combinations.
Humans are good at leveraging tools. LLMs are next level. They can manage orders of magnitude more tools perfectly. The Unix philosophy underpins the emerging AI-driven landscape.
Our data ecosystem, on the other hand, hasn’t even reached the maturity of 1969 Unix.
Codd, the inventor of the relational data model, discovered that breaking data up into coherent bundles and allowing users to stitch these together on the fly was a very smart way of delivering downstream flexibility. The relational data model appears to be an almost perfect data analogue to Unix tools. Unfortunately, it isn’t. For a relational model to work at scale, a monolithic structure needs to be imposed over these otherwise independent data bundles. In this case, composability is only skin deep.
For the past 50 years, we have made this architecture work for humans. It will not scale to meet the demands of AI agents.
From relational islands to monolithic schemas
Relational databases were our first serious attempt at data composability. Tables with primary and foreign keys gave us a disciplined way to relate pieces of information. Normal forms, constraints, and joins promised a universe where any report could be built by combining the right tables in the right way.
But there was a catch: you had to know the relationships ahead of time. Schema design is an act of prediction:
- which entities will matter,
- how they relate,
- what cardinalities we expect, and
- which queries must be fast.
Foreign keys encode a guess about which tables will be joined; indices and materialized views encode a guess about which usage patterns will matter.
The result is a paradox. Each table is its own island, but the archipelago is frozen into a monolithic environment defined at design time. Change the business, and you’re back to schema migrations, index rebuilds, and view redesigns. The data is “composable” in theory, but in practice, the cost of changing the composition is high.
OLAP: pre‑composed data for humans
OLAP technologies emerged to alleviate some of these problems for analytical workloads. OLAP cubes and modern variants organize data into multidimensional structures: time, region, product, customer, and so on. They are explicitly optimized for slicing, dicing, drilling down, and rolling up across those dimensions.
This works well for what it was designed for: fast, interactive exploration of known metrics along known dimensions. But it comes with the same predictive burden:
- You have to decide in advance which dimensions matter enough to model explicitly in the cube.
- You pre‑aggregate data along those dimensions so humans can drag, drop, slice, and pivot without waiting minutes for each query.
- You design measures and hierarchies with particular business questions in mind.
OLAP gave analysts far more power than raw SQL on a transactional database, but the end consumer was still a human being sitting in front of a dashboard. Humans can only juggle so many dimensions, filters, and edge cases at once. The whole stack – from schema, to cube, to dashboard – was designed around the assumption that a person would be the one doing the thinking.
It’s pre‑composed data: powerful within its boundaries, rigid outside them.
LLMs as semantics engines for data
Composability becomes far more interesting when the consumer is not a human, but an LLM‑driven agent.
We’re already watching LLMs make better use of Unix‑style tools than even expert engineers, simply because they can remember and orchestrate far more tools than a human can. The same thing is starting to happen with data. Instead of asking, “How can a human analyst understand this cube?”, we can ask, “How can an AI agent discover and exploit structure across many small, imperfect datasets?”
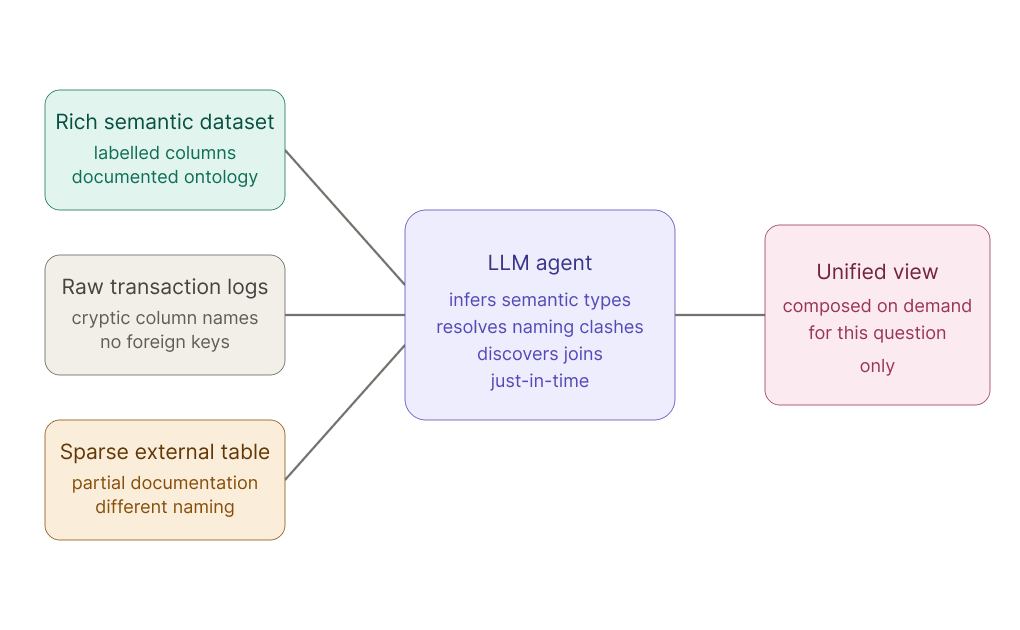
Recent work in data discovery and semantic matching shows that LLMs can uncover relationships that traditional methods miss. They can infer semantic types and linkages by looking at column names, values, and documentation, even when explicit foreign keys or shared IDs are absent. Techniques that serialize tables and metadata into text, then use LLMs to match queries to datasets, effectively treat the model as a semantics engine sitting on top of many loosely related tables.
In other words:
- One dataset has rich semantic labels and ontologies.
- Another is just raw logs or sparse transactional data.
- An LLM, given access to both, can infer how they relate, mapping column meanings, resolving naming inconsistencies, and identifying shared entities.
Where OLAP pre‑defines the joins and aggregations, an LLM can discover them just‑in‑time.
This is data composability: small, focused data pools, each with their own local logic, being stitched together on demand by an AI that can hold far more context in working memory than any human analyst.
Stop predicting and start composing
This shift is impacting how we design data systems.
Data designers need to stop trying to predict in advance what every consumer will want to do with their data. Historically, we had no choice: prediction was the only way to get performance. You over‑designed schemas, indices, cubes, and views because computation and human attention were scarce.
But our consumers are changing. The primary users of rich data infrastructure will very soon be AI agents, not humans. Those agents:
- Do not mind dealing with many small, specialized datasets.
- Can tolerate heterogeneous schemas, naming conventions, and partial documentation, as long as there is enough signal to infer structure.
- Can issue many exploratory queries in parallel to discover useful joins and aggregations before presenting a distilled result to a human.
In that world, the job of the data platform is less “anticipate every query” and more “make it cheap to compose anything with anything.” That pushes us toward a new paradigm: just‑in‑time optimization.
Instead of:
- Pre‑building every view and cube we can think of.
- Locking our data into rigid warehouse hierarchies.
We should aim for:
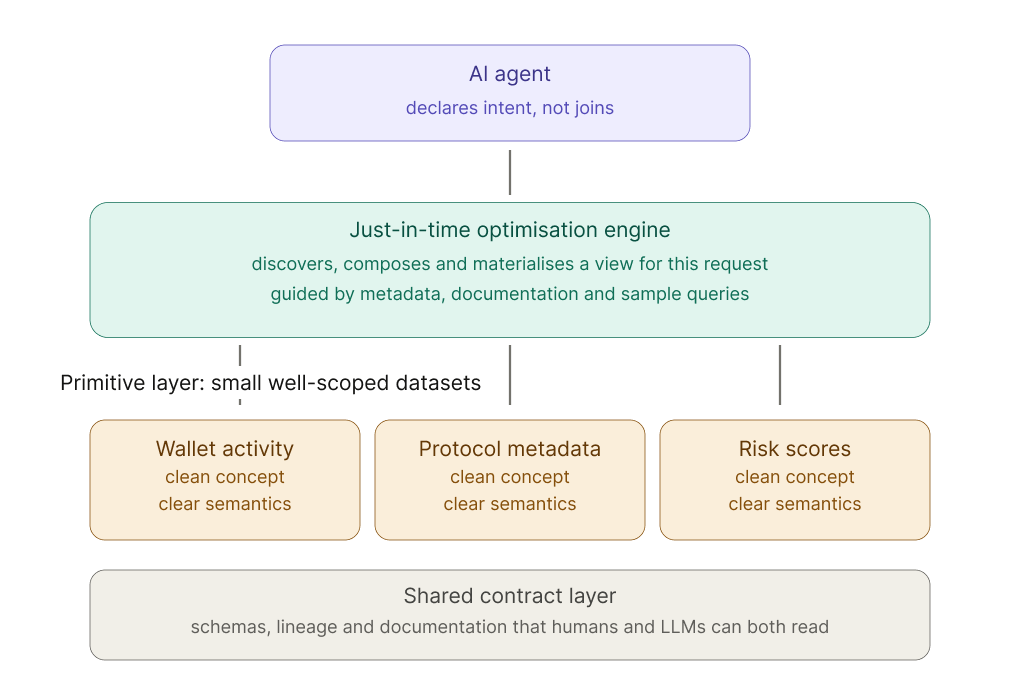
- Exposing small, well‑scoped datasets with clear semantics and lineage.
- Providing rich metadata, documentation, and sample queries that LLMs can consume.
- Building infrastructure that can materialize optimized views on demand, based on declarative intent from an agent.
An agent should be able to say, “I need a time‑series view of wallet activity for these addresses, enriched with protocol metadata and risk scores,” and have the platform assemble, optimize, and serve exactly that, rather than forcing the agent to stitch together ten raw tables manually.
This is the same pattern we saw with Unix: don’t over‑specify the workflows; just make sure the primitives compose cleanly.
Learning from Unix, again
The original Unix designers had an advantage that we are only now rediscovering: they assumed they didn’t know what users would want to do. So instead of building giant, purpose‑specific applications up front, they focused on a small number of design primitives – files, text streams, processes, and pipes – and made it trivial to wire them together.
Mainframe and VAX operating systems, by contrast, often concentrated power inside large subsystems and tightly coupled workflows. The environment made strong assumptions about usage patterns, so changing those patterns was expensive.
Today, data infrastructure looks more like a mainframe than like Unix. Warehouses, cubes, and dashboards encode many assumptions about how data will be used. When those assumptions change, as they always do, pay the price in migrations, re‑modeling, and brittle integrations.
The composability lesson is the same as before:
- Keep your units small and well‑focused: datasets that represent clean concepts, not gigantic denormalized blobs.
- Invest in simple, consistent interfaces: schemas, contracts, and metadata that both humans and LLMs can understand.
- Design for composition, not prediction: assume you don’t know what future agents will do, but give them the primitives to do almost anything.
Composability won once, when we applied it to tools. It is about to win again, when we apply it to data.
What this means for blockchain data
Blockchain data is already fragmented across contracts, chains, events, traces, token standards, and application-specific state.
For human users, that fragmentation is usually hidden behind dashboards, APIs, or prebuilt views. For AI agents, that model will not be enough. Agents need to discover, combine, and reason across many small datasets in real time.
That makes composability a data infrastructure problem.
The future of blockchain data is not a single, all-encompassing schema that anticipates every question. It is a system of well-scoped datasets, clear semantics, reliable metadata, and query surfaces that can be composed into new workflows as new workflows emerge.
That is how we think about Ormi’s role in the data stack: making blockchain data fast, reliable, and structured enough for applications and agents to build on without forcing every use case into the same shape.
About Ormi
Ormi is the next-generation data layer for Web3, purpose-built for real-time, high-throughput applications like DeFi, gaming, wallets, and on-chain infrastructure. Its hybrid architecture ensures sub-30ms latency and up to 4,000 RPS for live subgraph indexing.
With 99.9% uptime and deployments across ecosystems representing $50B+ in TVL and $100B+ in annual transaction volume, Ormi is trusted to power the most demanding production environments without throttling or delay.